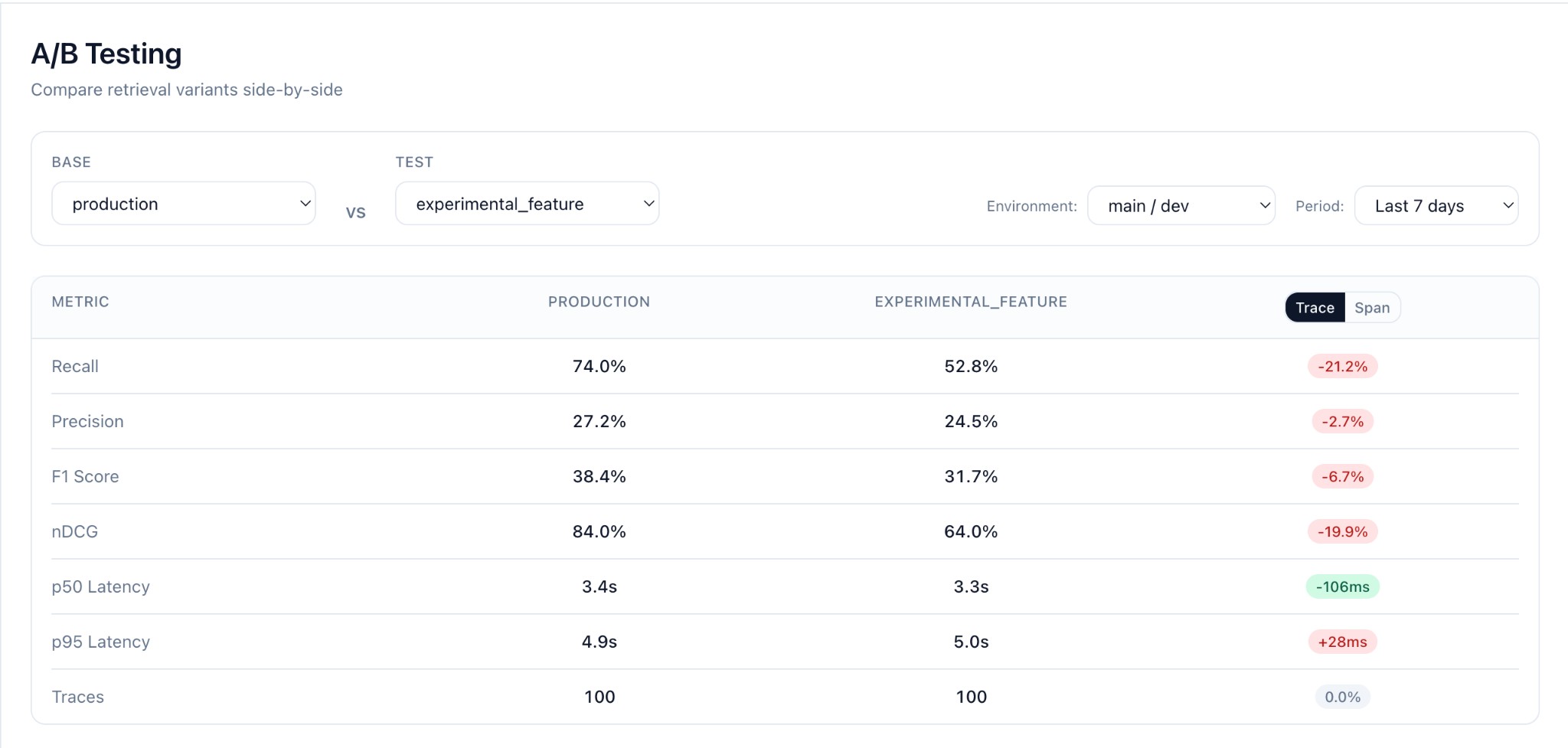
Compare embedding models, rerankers, or prompts on real traffic. Know which variant wins with statistical significance—in 1 hour, not 1 month.

Add a feature flag to your logs
# Variant A (baseline)
client.log(task=query, context=docs, metadata={"feature_flag": "baseline"})
# Variant B (new embeddings)
client.log(task=query, context=docs, metadata={"feature_flag": "new-embeddings"})That's it. Seer automatically groups and compares variants.
See also: Production Monitoring — track context quality in real time and get alerted when metrics drop.
Add feature flags. Compare variants. Ship with confidence.