Production-grade AI search
Auto-evaluate every retrieval, validate citations, and catch regressions before users do.
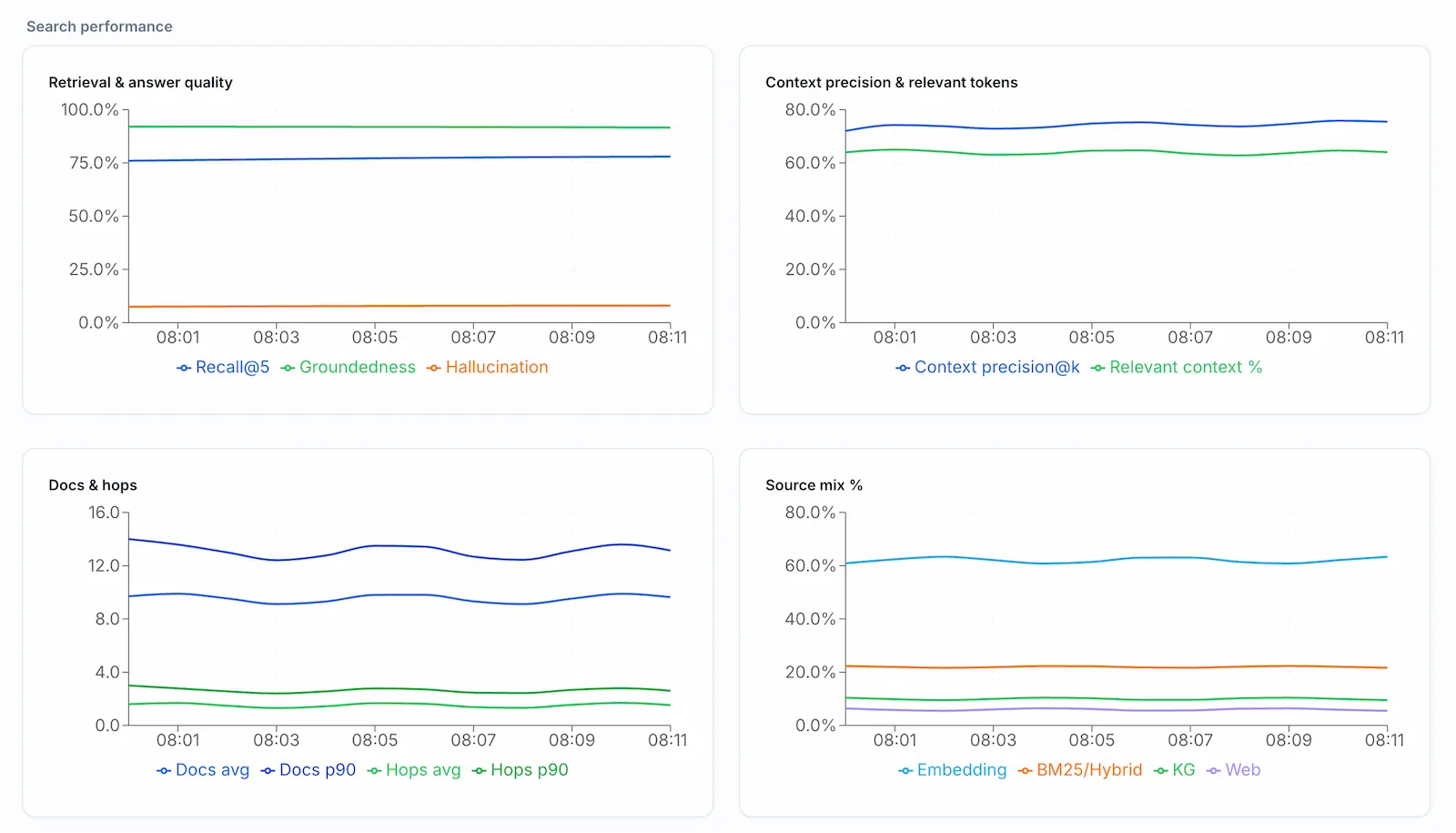
Auto-evaluate every retrieval, validate citations, and catch regressions before users do.
Seer’s 4B matches GPT‑5 on context evals with low cost and latency.
Evaluate diffs on unlabeled production traffic and wire evaluation into CI or staging rollouts.
Track recall, groundedness, and coverage in real time so regressions never blindside customers.
Evaluate retrieval algorithm updates on unlabeled data, measure lift across recall, precision, and groundedness, and ship the winning variant confidently.
Stream evaluator scores from live traffic to catch drift, route alerts, and keep a pulse on mission-critical search experiences.
Audit whether every answer cites the passages that actually cover each fact—perfect for regulated workflows in finance, healthcare, and legal.
Use Seer’s atomic fact breakdowns to spot missing content categories and prioritize new documents or data sources.
Feed evaluator artifacts into embedding retraining, cache tuning, and routing logic so search quality improves the more your users interact.
| Model | Accuracy | Macro F1 | Micro F1 |
|---|---|---|---|
| Qwen3-4B | 0.481 | 0.5104 | 0.539 |
| Seer (Qwen3-4B) | 0.777 | 0.86 | 0.87 |
| GPT-5 | 0.776 | 0.878 | 0.866 |
| GPT-5-chat | 0.750 | 0.865 | 0.848 |
| GPT-5-mini | 0.733 | 0.868 | 0.843 |
| GPT-5-nano | 0.628 | 0.721 | 0.752 |
| Seer (Qwen3-1.7B) | 0.661 | 0.7633 | 0.7789 |
| Monthly Evals | Seer-4B | Seer-1.7B | GPT-5 | GPT-5-mini | GPT-5-nano |
|---|---|---|---|---|---|
| 100k | $16 | $2 | $606 | $121 | $24 |
| 1M | $160 | $20 | $6,063 | $1,213 | $243 |
| 10M | $1,600 | $200 | $60,625 | $12,125 | $2,425 |
Fine-tuned open models deliver SOTA accuracy while staying private to your environment.
Run millions of evaluations for a fraction of closed-model pricing, enabling tighter iteration loops.
Small models scale on commodity GPUs or your own secure cloud with headroom for customization.
Book a 30-min walkthrough with live evaluator metrics on your data.